|
Junwei Zhou
I'm a first year Ph.D. student at Dartmouth College, advised by Prof. Yu-Wing Tai.
Previously, I have worked with Prof. Ming-Hsuan Yang, Prof. Lu Qi, Dr. Xueting Li at UC Merced, and Prof. Xinggang Wang at HUST.
I received my B.E. from Huazhong University of Science and Technology.
|

|
Research |
|
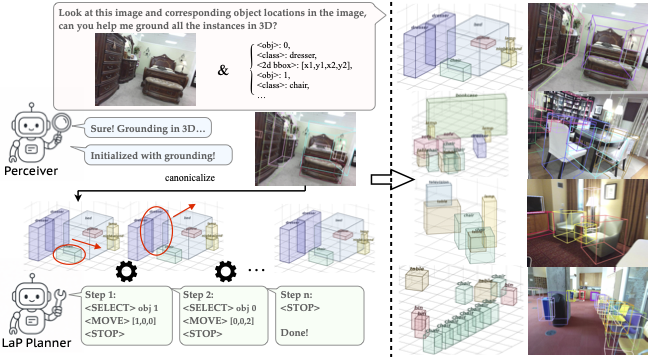
Perceive-then-Plan: Layout-as-Policy for Monocular 3D Scene Layout Estimation
Junwei Zhou, Yu-Wing Tai Arxiv, 2026 project page / arXiv We propose a perceive-then-plan framework with two VLMs (Perceiver and LaP Planner) for monocular 3D layout estimation, enabling both visual alignment and scene Coherence. |
|
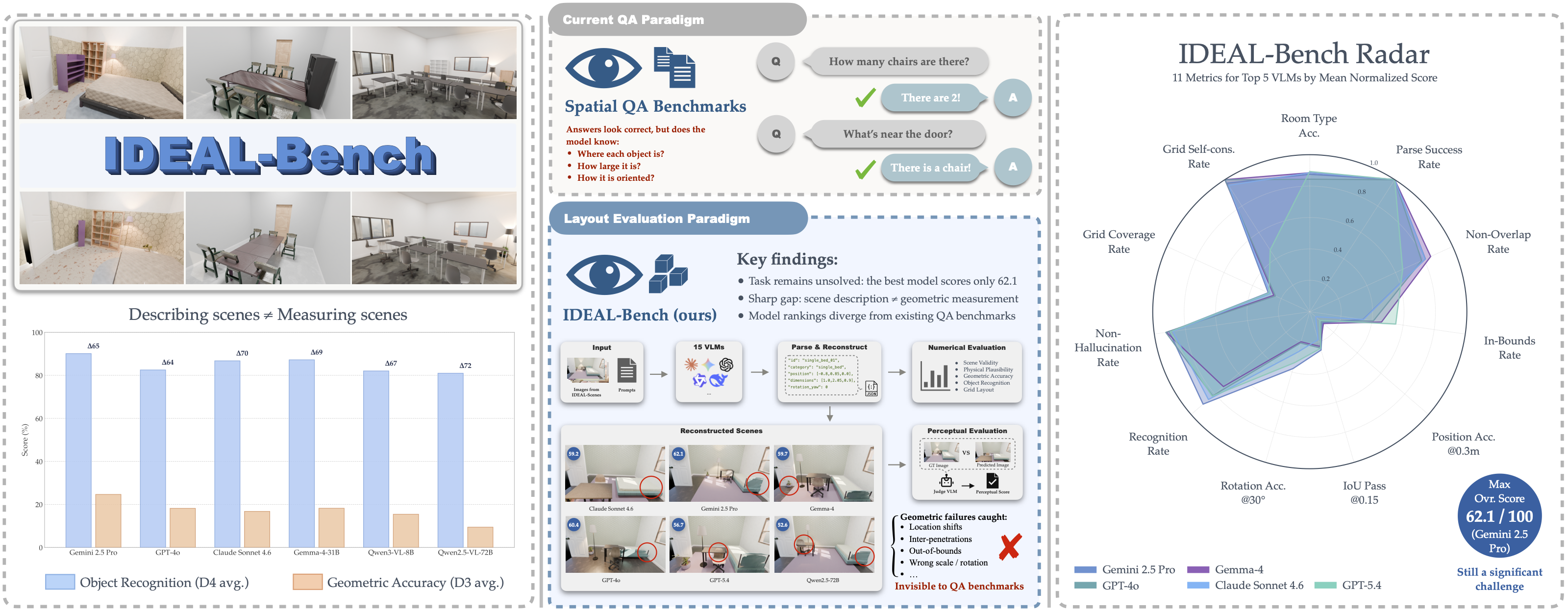
IDEAL-Bench: Indoor Dataset and Evaluation suite for Analyzing 3D Layout reasoning
Yuening Cai, Junwei Zhou, Youran Qu Yu-Wing Tai Arxiv, 2026 project page / arXiv We introduce IDEAL-Bench, a benchmark designed to evaluate true spatial understanding by requiring models to infer structured 3D scene layouts from a single image, addressing the limitations of existing benchmarks. |

|
GENA3D: Generative Amodal 3D Modeling by Bridging 2D Priors and 3D Coherence
Junwei Zhou, Yu-Wing Tai ECCV, 2026 project page / arXiv Intergrating 2D amodal completion and 3D generative modeling to achieve amodal 3D objects generation from multiple partial occluded input images. |

|
CoCo4D: Comprehensive and Complex 4D Scene Generations
Junwei Zhou, Xueting Li, Lu Qi, Ming-Hsuan Yang Arxiv, 2025 project page / arXiv Generating a comprehensive and complex 4D scene by dividing a 4D scene and progressive dynamic content extrapolation. |
|
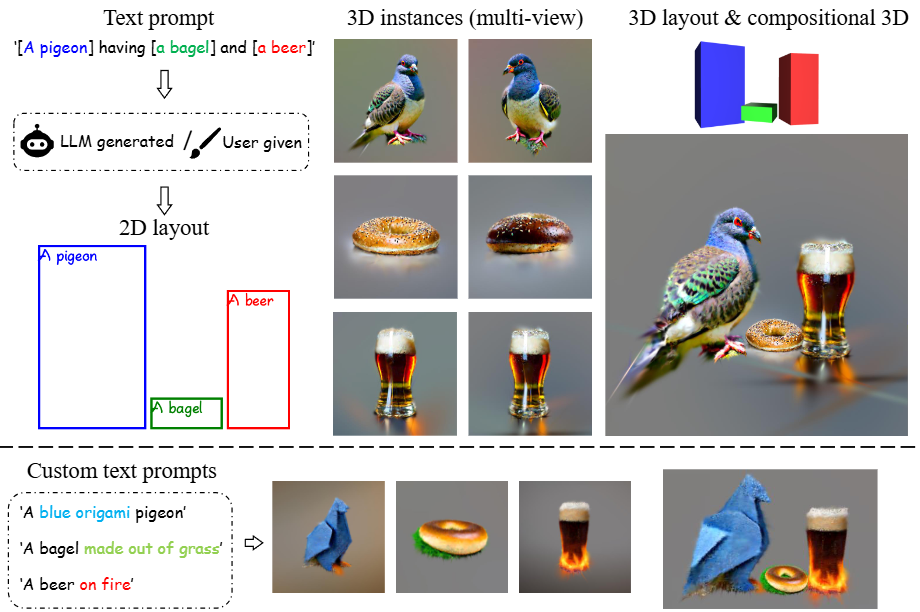
Layout-your-3D: Controllable and Precise 3D Generation with 2D Blueprint
Junwei Zhou, Xueting Li, Lu Qi, Ming-Hsuan Yang ICLR, 2025 project page / arXiv Given a text prompt describing multiple objects and their spatial relationships, our method generates a 3D scene depicting these objects naturally interacting with one another. |
|
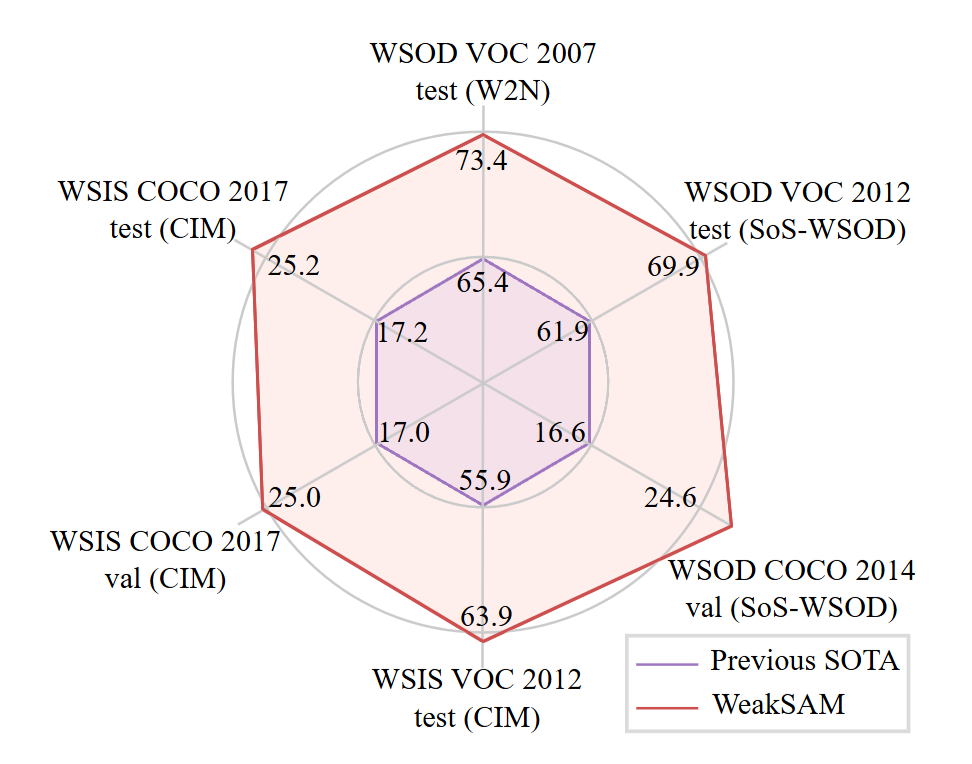
WeakSAM: Segment Anything Meets Weakly-supervised Instance-level Recognition
Lianghui Zhu*, Junwei Zhou*, Yan Liu, Xin Hao, Wenyu Liu, Xinggang Wang ACM Multimedia, 2024 project page / arXiv SAM in helping weakly-supervised instance perception task. |
Service |
Reviewer, ICLR 2025, 2026 | NeurIPS 2026
Reviewer, IJCV | TPAMI Teaching Assistant, Dartmouth College, COSC074 2025 Fall, 2026 Spring |
|
Website borrowed from JonBarron. |